Biography
Qianyu He (何千羽) is currently a fourth-year PhD candidate at Fudan University in the School of Computer Science. Her research interests primarily focus on enhancing the fundamental reasoning and instruction following capabilities of large language models (LLMs):
- Reasoning Model: Advancing research on incentivizing and understanding LLMs’ complex reasoning abilities.
- Instruction Following: Developing advanced methods for LLMs to follow complex instructions, ensuring more reliable human-LLMs interactions, and empowering autonomous completion of complex real-world tasks.
🌟 I am currently on the job market! I am actively seeking opportunities in research and industry positions related to large language models, reasoning, and instruction following. If you are interested in collaboration or have available positions, please feel free to contact me. For more details, please refer to my Resume.
- Reasoning Model
- Instruction Following
- Dancing 💃
PhD in CS, 2021-2026 (estimated)
Fudan University
B.S. in CS, 2017-2021
Fudan University
Experience
Topics: Reasoning Model, Long Chain-of-thought.
Projects: Seed-Thinking-v1.5, Doubao-1.5-pro-AS1-Preview
News
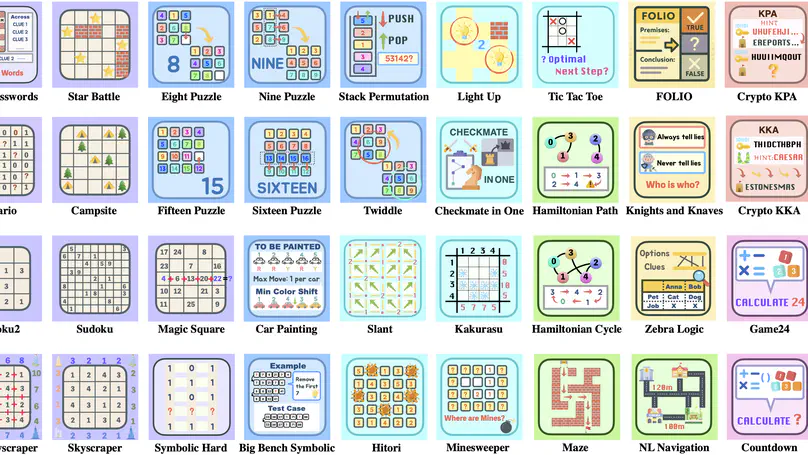
May. 2025 🎉 Checkout Enigmata, the first comprehensive suite tailored for improving LLMs with puzzle reasoning skills.
May. 2025 🎉 Checkout KORGym, A Dynamic Game Platform for LLM Reasoning Evaluation.
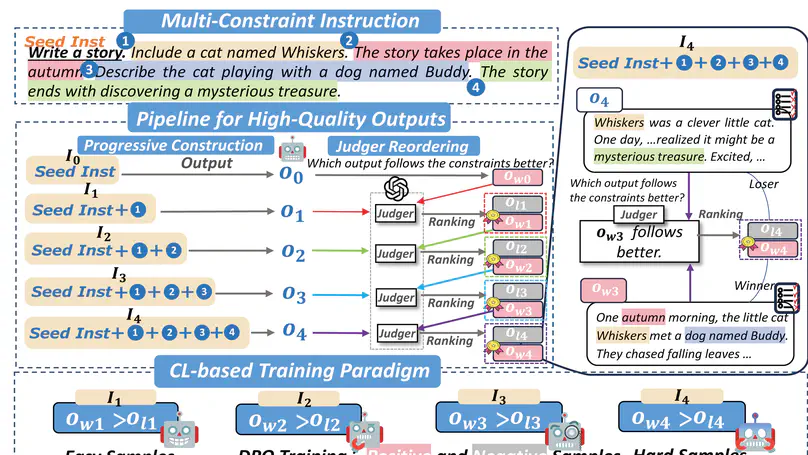
May. 2025 🎉 Two papers about how to enhance instruction following have been accepted by ACL 2025 findings! The first paper enhances the soft contraint following ability of LLMs and the second paper investigated the position bias in multi-constraint instruction following.
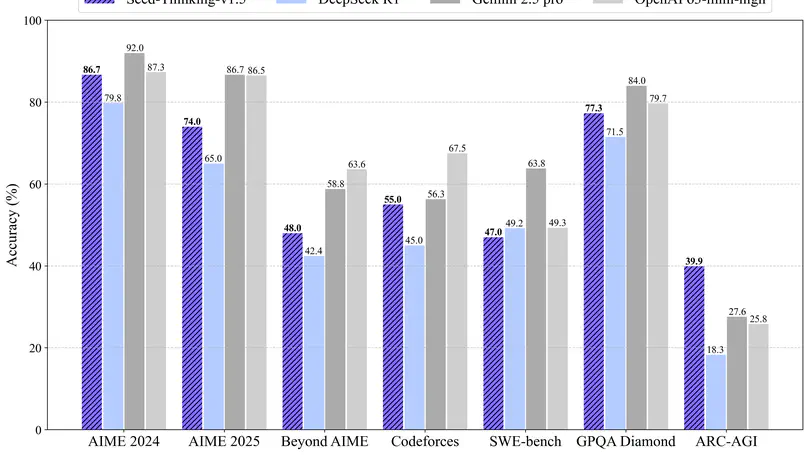
Apr. 2025 🎉 We introduce Seed1.5-Thinking, capable of reasoning through thinking before responding, resulting in improved performance on a wide range of benchmarks.
Mar. 2025 🎉 Our Instruction Following Benchmark CELLO was used by Hunyuan-Thinker-1-Preview for instruction following evaluation.
Jan. 2025 🎉 Congratulations on our paper Think Thrice Before You Act: Progressive Thought Refinement in Large Language Models accepted by ICLR 2025!
Nov. 2024 👀 Joined ByteDance Seed-LLM-Horizon as a research intern to work on reasoning models.
Aug. 2024 🎉 How to improve LLMs’ ability to follow Complex Instructions? Congratulations on our paper From Complex to Simple: Enhancing Multi-Constraint Complex Instruction Following Ability of Large Language Models got accepted to EMNLP 2024 findings!
May. 2024 👀 Joined StepFun Foundation Model Group as a research intern to work on LLM reasoning research.
May. 2024 🔔 Gave a talk at Alibaba Tongyi Lab, titled: “Complex Instruction Following Ability of Large Language Models”. Thanks for the invitation!